
PROJET PRINCIPAL
Indicateurs de présence des langues dans l’Internet

Résumé du projet
Jusqu’à récemment, la source de statistiques la plus consultée concernant l’utilisation des langues en ligne reposait sur des algorithmes d’analyse des sites web classés comme les plus visités. Bien que ces statistiques offrent un aperçu intéressant, elles peuvent ne pas refléter avec précision la présence des langues en ligne en raison de l’absence de prise en compte de la nature souvent très multilingue des sites web, lacune qui engendre d’importants biais.
En 2017, l’Observatoire de la diversité linguistique et culturelle dans l’internet a conçu une nouvelle approche qui pourrait aider à mieux suivre la progression et la prévalence des langues en ligne. Grâce à cette approche, nous avons pu identifier des indicateurs significatifs décrivant la présence de 343 langues dans l’internet.
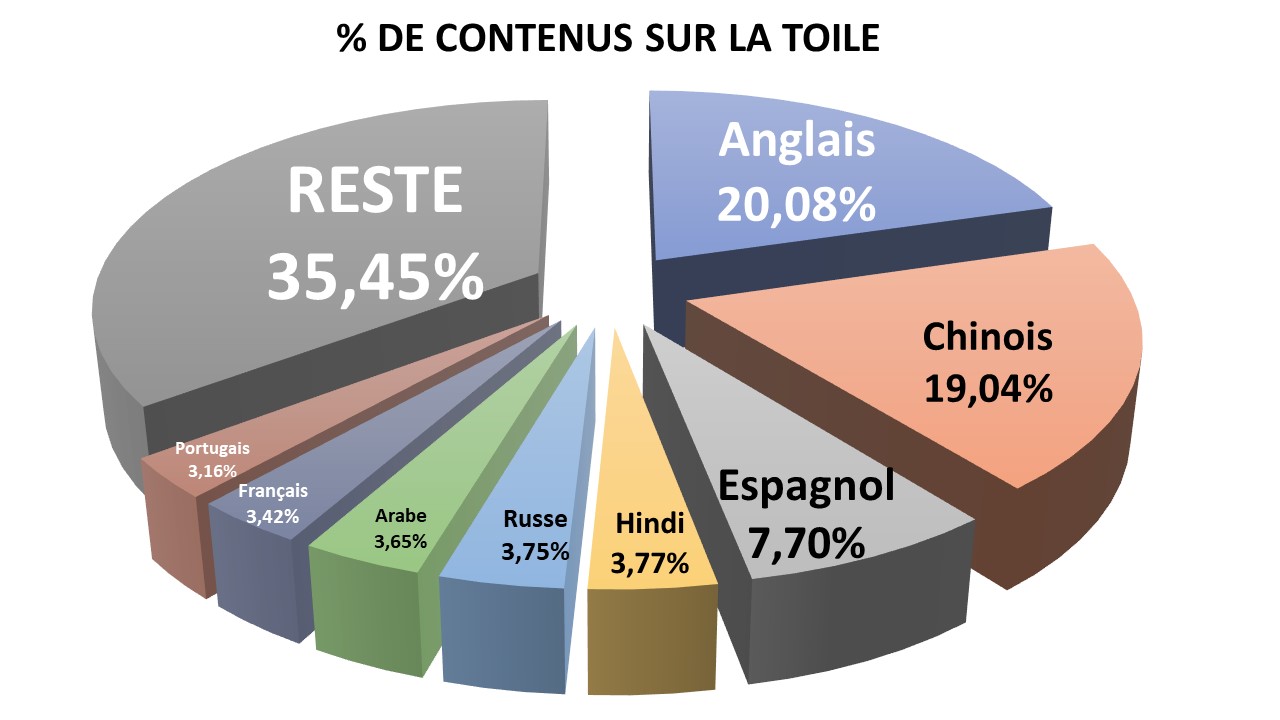
Les 10 langues les plus présentes dans la Toile
- Environ 20 % du contenu de la Toile est en anglais et 19 % en chinois
- Environ 7,7 % est en espagnol
- L’hindi, le russe, l’arabe, le français et le portugais représentent chacun autour de 3,5 % des pages web
* Sources : Ethnologue, UIT & une large collection de sources consultables dans notre matériel complémentaire. Intervalle de confiance ±20%.
* Derniers résultats de juillet 2025 (V6)
Les langues avec le plus fort pourcentage de contenus
| ISO | Langues | % INTERNAUTES | % LOCUTEURS L1+L2 | % LOCUTEURS CONNECTES L1+L2 | % CONTENUS | PRESENCE VIRTUELLE | PRODUCTIVITE CONTENUS |
| eng | Anglais | 15,48% | 14,13% | 70,66% | 20,08% | 1,42 | 1,30 |
| zho | Chinois Macro | 17,57% | 14,48% | 81,90% | 19,04% | 1,32 | 1,08 |
| spa | Espagnol | 6,63% | 5,22% | 48,48% | 7,70% | 1,48 | 1,16 |
| hin | Hindi | 4,27% | 5,68% | 89,53% | 3,77% | 0,66 | 0,88 |
| rus | Russe | 3,31% | 2,38% | 68,79% | 3,75% | 1,58 | 1,13 |
| ara | Arabe Macro | 4,36% | 4,08% | 67,75% | 3,65% | 0,89 | 0,84 |
| fra | Français | 3,05% | 2,91% | 77,76% | 3,42% | 1,18 | 1,12 |
| por | Portugais | 2,97% | 2,46% | 87,02% | 3,16% | 1,28 | 1,06 |
| jpn | Japonais | 1,55% | 1,15% | 93,00% | 2,23% | 1,93 | 1,43 |
| deu | Allemand Standard | 1,80% | 1,25% | 93,00% | 2,15% | 1,73 | 1,20 |
Résultats complets – Dernière mise à jour de juillet 2025 (V6)
L’UIT a mis à jour le pourcentage de personnes connectées pour 138 pays sur 227, 60 avec des changements négatifs et 78 avec des changements positifs. La plupart des changements sont inférieurs à 10 %, à quelques exceptions près. Certains changements ressemblent à des corrections de chiffres plutôt qu’à de véritables changements d’évolution : Antigua/Barbuda -14 % ; Kiribati +34 % ; Moldavie +17 % ; Myanmar +15 % ; Philippines +12 % ; Samoa -17 % ; Tadjikistan +21 % ; Tonga -13 % ; Vanuatu -24 %. Les données ont augmenté de 30 millions par rapport à la version précédente 5.2, mais les changements sont cosmétiques en termes de contenu.
Résultats précédents – Mise à jour de novembre 2024 (V5.2)
La précédente mise à jour, V5.2, de novembre 2024, suite aux mises à jour de l’UIT pour 62 pays, a impliqué 88 millions de nouveaux internautes L1+L2. Cependant, cela n’est pas suffisant pour apporter plus que des changements cosmétiques (sauf pour les langues du Malawi, qui est le seul pays africain à présenter une mise à jour, en fait une correction réduisant les individus connectés de 28% à 18%). La base de données est mise à jour avec les résultats de la version 5.2, cependant, pour ne pas surcharger la page, nous laissons les données de la version 5.1 en accès, y compris les données de cyber-géographie qui ne présentent pratiquement pas de changements. Pour plus de détails sur la version 5.2, consultez le blog.
Êtes-vous surpris de découvrir que le pourcentage de l’anglais dans la Toile tourne autour de 20 % ?
Si c’est le cas et si vous êtes curieux de comprendre cette question, consultez la page :
Vous êtes intéressé par une comparaison/évaluation de toutes les méthodes existantes identifiées pour mesurer les langues en ligne ? Vous voulez d’autres preuves du fait que les contenus en anglais représentent environ 20 % ?
Méthodologie
La nouvelle méthode de l’observatoire consiste à approcher indirectement la quantité relative de contenu Web par langue. Pour cela, elle prend également en compte des facteurs cruciaux qui sont souvent ignorés lors de la description de la présence d’une langue dans l’Internet, mais qui devraient être pris en compte pour éviter les erreurs ou les biais.
Tout d’abord, l’équipe examine l’existence probable d’une « loi économique » relative à la Toile, qui lie l’offre (c’est-à-dire les contenus Web disponible dans une langue) à la demande (c’est-à-dire le nombre de locuteurs de cette langue qui sont connectés à l’internet). Les résultats de nos études antérieures suggèrent que plus il y a de locuteurs d’une langue donnée connectés à l’Internet, plus il y a de pages web dans cette langue.
En outre, d’autres études antérieures montrent que les internautes préfèrent souvent communiquer dans leur langue maternelle lorsque du contenu est disponible dans cette langue, mais qu’ils sont heureux d’utiliser leur(s) deuxième(s) langue(s) en l’absence de ce contenu. Dans certains cas, les internautes peuvent également créer du contenu dans leur deuxième langue pour des raisons économiques et utiliser des services de traduction pour ce faire.
La présence d’une langue en ligne est également liée à l’importance du trafic Internet dans différents sites, au nombre d’abonnements à des réseaux sociaux et aux progrès réalisés par différents pays en termes de services citoyens liés à l’Internet. Les indicateurs de présence dans l’internet créés par les chercheurs prennent en compte l’ensemble de ces facteurs, ce qui permet de dresser un tableau plus détaillé de l’ampleur et des modalités de la présence de différentes langues dans l’internet.
Cybergéographie des familles de langues
Une analyse de l’évolution linguistique de l’Internet d’un point de vue géographique.
Indice de cyber-mondialisation (ICM)
L’indice de cyber-mondialisation est un indicateur stratégique de l’avenir d’une langue dans l’Internet. Il est défini comme suit :
ICM (L) = (L1 + L2)/L1(L) x S(L) x C(L) où:
(L1+L2)/L1 (L) est le taux de multilinguisme de la langue L
S(L) est le pourcentage de pays ayant des locuteurs de la langue L
C(L) est le pourcentage de locuteurs de la langue L connectés à l’Internet
Notes de mise à jour et versions précédentes
Si vous souhaitez avoir une meilleure idée de la méthode sans lire les articles publiés et indépendamment des dernières données, rendez-vous sur la version 3.0 pour laquelle un effort d’explication et d’affichage des résultats a été réalisé.
Version 5.1 (avril 2024)
Mises à jour dans cette version
1) La base de données Ethnologue #27 de mars 2024 a été utilisée pour les données démolinguistiques. L’indicateur de soutien numérique fourni par Ethnologue dans le cadre de cette base de données a également été mis à jour. Les chiffres de l’UIT concernant le pourcentage de personnes connectées à l’internet par pays ont été mis à jour.
2) 19 nouvelles langues atteignant le seuil de 1 million de locuteurs L1 ont été ajoutées au modèle, pour un nouveau total de 361 langues :
Malais d’Amboine abs
Boulou bum
Bangala bxg
Efik efi
Basque eus
Gbaya gba
Irlandais gle
Pidgin anglais ghanéen gpe
Iban iba
Krio kri
Créole libérien lir
Créole malais mfp
Bas saxon nds
Malais de Nouvelle Guinée pmy
Créole de Guinée-Bissau pov
Arakanais rki
Sango sag
Scots sco
Tok Pisin tpi
3) Les changements dans les résultats du modèle sont peu nombreux.
- En termes de contenu, l’anglais consolide légèrement sa première position par rapport au chinois.
- L’hindi prend la tête des langues en 4ème position, laissant l’arabe derrière le russe et avant le français et le portugais.
Version 4.0 (mai 2023)
Mises à jour de la méthodologie dans cette version
1) Dans l’intégration des données Ethnologue, Arabe Standard (arb) n’a pas été calculé comme deuxième L1 pour tous les pays concernés, à l’exception de l’Arabie Saoudite. La raison en est que l’un des principes fondateurs du modèle est qu’il n’y a qu’une seule L1 et que la macro-langue ara ne peut pas inclure deux fois la même population en tant que L2.
2) En ce qui concerne l’inclusion de l’indicateur de soutien numérique (DLS) de la source Assessing Digital Language Support on a Global Scale, il est défini pour chaque langue, ce qui soulève la question de savoir comment gérer les macro-langues. La décision prise a été d’attribuer à chaque macro-langue l’indicateur le plus élevé de l’ensemble des langues appartenant à cette macro-langue.
3) L’indicateur interface du modèle est maintenant calculé comme la moitié de la somme de l’indicateur précédent plus le DLS (qui a une valeur entre 0 et 1) et en recalculant les résultats pour les normaliser à 100%. Cet ajout réduit le biais de cet indicateur en augmentant potentiellement le poids de nombreuses langues qui étaient absentes des interfaces d’application ou des programmes de traduction et dont le poids était nul. Pour le reste des langues, il n’induit pas de changements notables.
Version 3.2 (avril 2023)
Mise à jour par l’UIT du % de personnes connectées par pays
Résumé
- Le pourcentage total de personnes connectées dans le monde est passé de 64 % à 67 % en un an.
- L’UIT a repris l’offre d’estimations dans les pays où aucune donnée officielle n’est proposée par le gouvernement.
- Nombreux changements importants dans les données de connectivité par pays, avec une forte croissance ou baisse.
- Pratiquement aucun changement pour les premières langues
- La forte croissance de la connectivité en Afrique entraîne une augmentation de plus de 10 % des langues africaines
- Les signes de progrès des moins connectés commencent à apparaître : le français progresse grâce au progrès de connectivite de l’Afrique, ainsi que les langues africaines ; les langues asiatiques continuent de progresser, à l’exception du chinois.
- La croissance de la population arabe connectée s’est arrêtée
Version 3.1 (août 2022)
Mise à jour par la Banque mondiale (% de personnes connectées par pays), y compris comparaison avec V3.c
Version 3.c (août 2022)
Correction d’une erreur dans la V3, avec un impact marginal
Version 3.0 (mars 2022)
Remaniement du modèle, obtention de la version finale, tous les biais importants étant maintenant contrôlés.
Résumé
Plus qu’une nouvelle version, il s’agit de l’arrivée à maturité de la méthode, puisque tous les biais sont désormais maîtrisés à un seuil acceptable, et que les indicateurs produits sont fiables dans un intervalle de confiance de ±20%.
L’Observatoire a le plaisir de partager les résultats de la version 3 de son modèle de calcul des indicateurs de présence des langues dans l’Internet, qui, comme pour la version 2, annoncée en 2021, traite les 329 langues de plus d’un million de locuteurs natifs.
Un intervalle de confiance de ±20% peut sembler large si l’on applique les critères d’autres travaux statistiques, mais pour les données relatives à la place des langues dans l’Internet, un sujet qui a toujours été très difficile à approcher et victime d’une désinformation chronique, c’est un exploit.
Tous les résultats sont disponibles sous licence CC-BY-SA 4.0.
Version 2.0 (2021)
Amélioration du contrôle des biais du ce qui permet d’ atteindre 329 langues
Résumé
En février 2021 démarre un projet de mesure du portugais dans l’Internet et de comparaison avec d’autres langues, coordonné par la Chaire UNESCO sur les politiques publiques pour le multilinguisme, réalisé par l’Observatoire de la diversité linguistique et culturelle dans l’Internet et sous le soutien du Département culturel et éducatif du ministère brésilien des Affaires étrangères dans le cadre de l’Institut international de la langue portugaise. Les premiers résultats seront produits d’ici mai 2021 et les produits complets d’ici août 2021.
L’étude bénéficiera de quelques améliorations notables:
– Utilisation de la dernière base de données Ethnologue pour les données démolinguistiques
– Traitement des locuteurs de L2 par pays au lieu de global
– Actualisation et extension des indicateurs de langue et de pays
– Extension de la couverture des langues
Version 1.2 (2019)
Offre une comparaison entre les résultats de 2015, 2016 et 2017 en utilisant la version 2017 et en jouant avec les données de l’UIT des années précédentes.
Notes méthodologiques
1 – Seules les données de l’UIT ont été mises à jour en 2016 et 2017
2- Une comparaison complète nécessiterait la mise à jour des données démo-linguistiques ET des différents micro-indicateurs de présence de langues ou de pays
3-. Cependant, les données mises à jour sont celles qui ont le plus d’importance dans le modèle et offrent donc une indication crédible des tendances
4- Il est important de comprendre que les pourcentages d’augmentation ou de diminution ne sont pas absolus, mais relatifs au reste des langues.
Synthèse des résultats
En ce qui concerne les langues les plus puissantes, les évolutions sont lentes même s’il existe une nette différence entre
les langues qui progressent très fortement : Hindi et Malais
les langues qui progressent fortement : Le coréen, l’ourdou, l’arabe et le portugais
les langues qui continuent leur progression régulière ; l’espagnol et le polonais
les langues en déclin régulier : le japonais, le russe et le chinois
les langues en fort déclin : l’allemand, le français, l’italien et dans une moindre mesure l’anglais.
Notons que l’arabe passe devant le japonais et l’ourdou devant le polonais et le coréen
Dans les meilleures progressions apparaissent les langues africaines et asiatiques, puis apparaissent le kabyle, l’arabe, le turc et l’arménien en forte progression.
Quelques langues européennes suivent en milieu de classement et en progression stable comme le roumain, l’ukrainien, le portugais, l’albanais et l’espagnol.
Le polonais est la dernière langue en faible progression et se produit le premier faible déclin du russe et du chinois, suivi de l’hébreu et du suédois
La plupart des langues occidentales affichent logiquement un déclin relatif, conséquence de la saturation des connexions (90% des personnes connectées)
L’anglais poursuit un déclin régulier et le français encore plus, signe que l’Afrique francophone est lente dans sa lutte contre la fracture numérique.
En fin de classement, un fort recul des langues locales des pays asiatiques ou africains (souvent francophones) qui restent bloquées dans la fracture numérique.
Version 1.0 (2017)
Début d’une nouvelle méthode pour 129 langues.
Résumé
L’observatoire a mesuré la place des langues latines, de l’anglais et de l’allemand dans l’Internet, entre 1997 et 2007.
Après 10 ans d’éclipse, due à l’évolution des moteurs de recherche, nous sommes de retour, grâce au soutien de l’Organisation Internationale de la Francophonie et de MAAYA, avec une nouvelle méthode de production d’indicateurs pour les 140 langues de plus de 5 millions de locuteurs.
Les projets d’OBDILCI
- Indicateurs de la présence des langues dans l’Internet
- Les langues de France dans l’Internet
- Le français dans l’Internet
- Le portugais dans l’Internet
- L’espagnol dans l’Internet
- IA et multilinguisme
- gTLDs linguistiques
- DILINET
- Projets pré-historiques
- Mort numérique des langues