PROJET PRINCIPAL-ANGLAIS@WEB
Anglais@Web : un biais historique

Quel est le pourcentage réel de l’anglais dans le Web ?
Vous êtes surpris de voir nos résultats montrant le pourcentage de pages Web en anglais autour de 20% alors que vous voyez partout, dans les médias et les requêtes aux moteurs de recherche, des valeurs entre 50 et 60% ?
En effet, vous êtes témoin d’une mésinformation profonde et ancienne qui mérite attention et examen. Cette page offre les informations nécessaires pour mieux comprendre les enjeux.
Cette désinformation est le résultat d’une combinaison de facteurs :
- Une source biaisée : W3Techs.
- Le fait que cette source soit une entreprise très compétente qui offre des statistiques utiles et fiables sur les technologies Web et qui propose également des statistiques sur les contenus par langue.
- Le fait que cette source fonctionne depuis 2011 et qu’elle soit restée totalement seule à fournir des données sur les contenus par langue jusqu’en 2017.
- Le succès marketing et médiatique de cette source qui a été amplifié par le système de classement des moteurs de recherche, Wikipedia et Statista, sans la prudence requise dans les deux derniers cas.
- La faible visibilité de notre travail et de notre site web par rapport à W3Techs (sauf dans les moteurs de recherche scientifiques tels que GoogleScholar).
W3TECHS, une source biaisée en ce qui concerne les langues
W3Techs est une société qui propose des informations sur l’utilisation de différents types de technologies sur le web et prétend fournir la source d’information la plus fiable, la plus étendue et la plus pertinente sur l’utilisation des technologies web.
Cette affirmation de fiabilité est totalement justifiée, à l’exception d’un élément qui n’est pas précisément une technologie web : le pourcentage des langues dans les contenus. La méthode utilisée par W3Techs consiste à parcourir quotidiennement un échantillon de sites web et à recenser la présence des différentes technologies web analysées :
Content Management
Server-side Languages
Client-side Languages
JavaScript Libraries
CSS Frameworks
Web Servers
Web Panels
Operating Systems
Web Hosting
Data Centers
Reverse Proxies
DNS Servers
Email Servers
SSL Certificate Authorities
Content Delivery
Traffic Analysis Tools
Advertising Networks
Tag Managers
Social Widgets
Site Elements
Structured Data
Markup Languages
Character Encodings
Image File Formats
Top Level Domains
Server Locations
Le dernier élément de la liste est Content languages ; en fait, les langues ne sont pas vraiment une technologie web et cela a des implications qu’il faut comprendre. À la différence des technologies web, il ne s’agit pas d’une question binaire d’utilisation ou de non-utilisation dans un site web spécifique : plusieurs langues différentes peuvent être utilisées dans le même site web, ce qui constitue une différence importante que nous explorerons plus loin.
La méthodologie utilisée par W3Techs pour son enquête consiste à utiliser Tranco (la liste du million de sites web les plus visités) comme échantillon et à appliquer quotidiennement son algorithme de présence des langues sur cet échantillon. Il convient de noter qu’auparavant, et jusqu’en 2022, date à laquelle il a été mis fin à cette offre, la liste des 10 millions de sites web les plus visités fournie par Alexa était utilisée. Il convient également de noter que si l’hypothèse selon laquelle l’extrapolation du million de sites web les plus visités à l’ensemble du domaine du web (qui compte plus de 200 millions de sites web) est valide pour les technologies Web, ce n’est pas le cas pour les langues des sites web, car il est probable que les sites web les plus visités concentrent l’utilisation des langues les plus utilisées, et en particulier de l’anglais, ce qui crée un effet de loupe.
Concentrons-nous donc sur les différents biais liés à l’utilisation de la méthode sur les technologies web pour les langues. Il s’agit de différents biais qu’il convient de prendre en considération :
- Le biais de reconnaissance de la langue. Les algorithmes de reconnaissance linguistique ont un taux d’erreur considéré comme inférieur à 10% et ont tendance à reconnaître l’anglais au-dessus de sa prévalence réelle. Il s’agit d’un biais marginal bien qu’il favorise l’anglais.
- Le biais d’échantillonnage. Un million de sites web représentent moins de 0,5 % de l’univers web total et ne peuvent en aucun cas être considéré comme représentatif de l’ensemble. En fait, il favorise les langues les plus utilisées sur le web et en particulier l’anglais.
- Calcul des langues à partir des sites web au lieu des pages web. Le calcul correct des langues dans les contenus du Web doit être effectué sur les pages web, en divisant le nombre total de pages web dans une langue donnée par le nombre total de pages web sur la Toile. Il faut admettre que la taille du Web, estimée à plus de 40 milliards de pages, rend le calcul presque impossible et la simplification de la méthode est compréhensible. Mais il y a une condition à respecter pour que cette simplification soit réalisable : il faut tenir compte du fait que de nombreux sites web sont multilingues et que cette propriété doit être prise en compte dans la méthode afin d’éviter un énorme biais en faveur de l’anglais (le biais de multilinguisme qui est le biais principal de W3Techs, voir ci-dessous).
- Il existe un autre biais dans ce scénario de calcul par sites web au lieu de pages web : le biais de la page d’accueil. Le choix, fait par W3Techs, d’appliquer l’algorithme de reconnaissance à la page d’accueil du site web analysé comporte des risques élevés. Il est courant que de nombreux sites non anglophones s’efforcent d’inclure du texte anglais dans leur page d’accueil, que ce soit par synthèse (comme cela se fait couramment pour les résumés d’articles scientifiques rédigés dans une langue autre que l’anglais) ou par accident (boutons en anglais, par exemple). Il est donc possible que l’algorithme identifie par erreur cette page d’accueil comme étant en anglais.
- Le dernier biais dans ce scénario est la classification par erreur de sites web dans une langue autre que l’anglais comme étant anglais. Cela peut se produire soit parce que la page d’accueil contient du texte en anglais (cas précédent), soit aussi parce que le site web ne fonctionne pas et qu’il est tout de même classé comme site web anglais en raison d’un message en anglais signalant l’erreur. L’importance de ce biais pourrait être de l’ordre de 10 %.
Un autre point remet en cause les résultats de W3Techs. W3Techs présente les résultats en termes de pourcentage pour 38 langues, suivi d’une liste triée par contenus décroissant de quelques 200 langues pour lesquelles il rapporte un chiffre inférieur à 0,1% pour chacune d’entre elles.
Cependant, si l’on fait la somme des pourcentages des 38 premières langues (le 23/04/2024), le résultat est exactement 99,90%. Cela signifie que les 200 autres langues représentent, ensemble, moins de 0,1 % du Web, ce qui semble assez étrange, car cela implique qu’en moyenne ces 200 langues représenteraient individuellement quelque 0,0005 %, ce qui semble peu plausible.
À titre de comparaison, si nous vérifions le pourcentage de contenu restant hors les 362 langues que nous calculons dans notre modèle, il représente 1,76% dans notre dernière version, un chiffre cohérent avec le fait que le reste des langues correspond aux 3,42% restants de la population L1+L2 et aux 2,65% restants de la population connectée.
Le biais principal de W3TECHS : ne pas accorder l’attention nécessaire au multilinguisme des sites web
La méthodologie de W3Techs est décrite ici : https://w3techs.com/technologies. Il ne s’agit pas d’une description entièrement détaillée et transparente comme le ferait un article scientifique. On comprend que chaque site web se voit attribuer une seule langue. Il est également supposé que la langue de travail par défaut est l’anglais, ce qui implique que les sites web multilingues (tel que Facebook) sont classés comme des sites en anglais. La méthodologie fait référence aux « sites web pertinents » mais il n’y a aucune description du traitement des sites qui ne répondent pas au critère et nous pouvons également supposer qu’une proportion de sites web avec des erreurs peut être reconnue comme des sites en anglais (notez que dans l’échantillonnage Tranco nous avons identifié jusqu’à 20% de sites web avec des erreurs, que ce soit 404 ou autres).
Nous avons analysé plus avant les conséquences de ce biais et même trouvé un moyen de le corriger ; l’analyse est publiée dans l’article publié dans Forum for Linguistic Studies, 6(5), 201–212 “Is it True that More Than Half of Web Contents are in English? If Web Multilingualism is Paid Due Attention, then No!“ (version française). Notez que la correction des biais conduit à un pourcentage pour l’anglais proche de celui calculé par OBDILCI. Il convient également de noter que l’article fait référence à deux autres séries de données concernant les contenus en anglais qui sont dans la même fourchette (20% – 30%). L’un provient d’un article scientifique portant sur les sites web situés dans les domaines de premier niveau de l’Union européenne (avant le Brexit et incluant les sites des pays de langue anglaise), l’autre d’une autre société de logiciels, Netsweeper, qui semble analyser les pages web plutôt que les sites web (ce qui protège du biais sur le multilinguisme) et qui fait état d’un énorme échantillonnage de 15 milliards de pages web. Si vous êtres intéressés par une description de l’ensemble des méthodes existantes, consultez cette publication faites à la réunion UNESCO LT4ALL de 2025.
Nouveau (juin 2026) : Si vous êtes intéressés par les résultats d’une mesure réalisée sur le même échantillon que W3Techs mais avec gestion du multilinguisme, consultez cette section sur le projet MECILDI où vous verrez confirmation d’une proportion de pages web en anglais de 20%.
Si vous préférez une démonstration simple, illustrée par un exemple, à la lecture d’un article scientifique, ou à l’analyse du nouveau projet MECILDI, voici le lien :
MISE À JOUR IMPORTANTE À CE SUJET (juillet 2026) : Nous avons désormais analysé le même échantillon que W3Techs et constaté que le pourcentage de pages web en anglais s’élève à 20,13 %, ce qui confirme nos prévisions. Le pourcentage de sites web disposant d’une version en anglais s’élève à 67,52 %. Que signifie alors le chiffre avancé par W3Techs, à savoir 49,6 % ? Certainement pas le pourcentage de pages web, mais ce chiffre est trop court pour désigner le pourcentage de versions en anglais sur les sites web… Il est impossible de le déterminer, compte tenu du manque de documentation sur la méthode utilisée. Nous soupçonnons que ce chiffre vise un concept de « pourcentage de sites web de l’échantillon Tranco ayant l’anglais comme « langue principale ». Le concept de langue principale s’applique aux êtres humains et est également appelé langue maternelle ou première langue. Cependant, ce concept s’applique difficilement aux sites web ; dans les sites multilingues, c’est l’utilisateur qui détermine quelle est la langue principale, soit implicitement (le site web détecte la langue par défaut du mobile ou de l’ordinateur), soit explicitement en sélectionnant l’option de langue de son choix dans un menu de langues (ou de pays). Si vous souhaitez en savoir plus sur notre nouvelle ligne de recherche et ses nouveaux indicateurs sur le multilinguisme sur le Web, consultez notre nouveau projet phare MECILDI.
Anglais@Web : un biais historique
La situation de surévaluation de la réalité du pourcentage de contenus en anglais n’est pas nouvelle. En fait, elle existe pratiquement depuis la naissance du Web. Les courbes suivantes montrent la différence entre ce que notre observatoire a mesuré et comment les médias rapportent ces données.
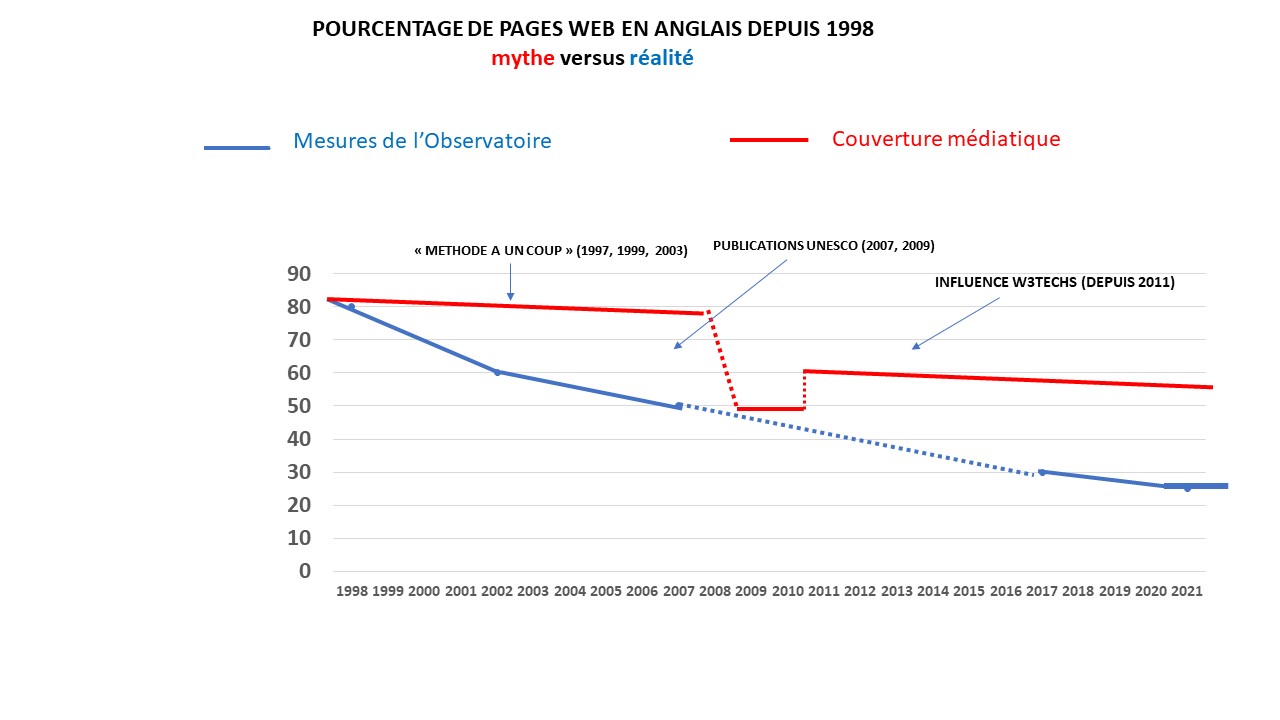
Cette situation a été documentée dans de nombreux articles évalués par des pairs depuis le début. Vous pouvez consulter par exemple :
- “Twelve years of measuring linguistic diversity on the Internet: balance and perspectives”, UNESCO publications for the World Summit on the Information Society. CI-2009/WS/1- (aussi en français – Русский)
- “Internet and linguistic diversity: the cyber-geography of languages with the largest number of speakers” in LinguaPax Review 2021, Language Technologies and Language Diversity, page 9. Also, in Spanish and Catalan.
- “Resource: Indicators on the Presence of Languages in Internet”, SIGUL2022 a workshop of LCREC22, Marseille, 6/2022 – français, español, portuguese.
- “Cyber-geography of languages. Part 1: method, results and focus on English”, International Review of Information Ethics, vol. 32 no. 1 (2022): Emerging Technologies and Changing Dynamics of Information (ETCDI) special issue.
- MECILDI : indicateurs de langues et de multilinguisme pour toute série de sites web, avec une attention particulière au multilinguisme – Application sur TRANCO et comparaison avec W3Techs, ResearchGate Preprint, 5/2026
Le fait que des autorités comme Wikipedia ou Statista préfèrent citer des chiffres non scientifiques plutôt que des chiffres validés par des pairs fait clairement partie du problème. Dans les deux cas, nous avons essayé d’ouvrir les yeux de ces fournisseurs de sources. Dans le cas de STATISTA notre courrier bien documenté est resté sans réponse et nous partageons avec d’autres la vision que la gestion des sources par STATISTA pose de graves problèmes éthiques dans le champ de la recherche. Dans le cas de Wikipedia des progrès ont finalement été réalisés.
UN REGARD SUR LE CONTEXTE ET LE RECOURS À UNE CERTAINE RATIONALITÉ
Quel est le contexte de ce thème ? D’une part, W3Techs montre, dans sa page historique, un pourcentage d’anglais dans le web quasiment stable de 2011 à 2024, entre 50 et 60%. A noter que jusqu’à récemment, cet histogramme commençait en 2011. D’autre part, l’Internet a évolué, de 2011 à 2024, avec les chiffres suivants (sources : InternetWorldStats pour 2011 et OBDILCI pour 2024, à noter qu’il s’agit de chiffres L1+L2).
En 2011
- Le nombre de personnes connectées dans le monde est de 1 966 514 816 (28,7 % de la population mondiale).
- Dont le nombre d’anglophones connectés est de 536,6 M (27,3% des personnes connectées).
En 2024
- Le nombre de personnes connectées dans le monde est de 6 800 888 461 (63,19 % de la population mondiale).
- Dont le nombre d’anglophones connectés est de 1 186 451 052 (15.79 % des personnes connectées).
Cela représente une baisse relative des anglophones connectés à l’Internet de 72,8%. Certes, le nombre d’internautes anglophones a largement augmenté en 13 ans, mais son augmentation est très inférieure à celle de la somme des internautes des autres langues (pour information, selon l’ensemble de données Ethnologue #27, les anglophones L1+L2 représentent 1 515 231 760 personnes, soit 14,13 % du total des locuteurs L1+L2). Pour que les contenus en anglais restent stables en proportion dans ce contexte, cela signifierait qu’ils ont compensé ce déclin relatif en augmentant la production de contenus par utilisateur de 72,8% !
En 2024, résultat de l’évolution de la démographie de l’internet, le pourcentage de locuteurs du chinois connectés a dépassé celui des locuteurs de l’anglais et il est maintenant de 17,41% et la même valeur pour les locuteurs en hindi est de 4,34%. Ensemble, ils représentent plus de 20% des internautes et selon les chiffres de W3Techs ils ne représenteraient que moins de 1,4% des contenus : c’est absurde.
Selon notre dernière mesure (V5.1, mars 2024), si l’on additionne les internautes qui parlent chinois, hindi, arabe, malais, bengali, turc, vietnamien, urdu, persan ou marathi, on atteint 35,81% du total des internautes. Si l’on additionne les contenus, on obtient 34,45%.
Pour les mêmes langues, W3Techs comptabilise moins de 8% des contenus: : chinois : 1,3%, hindi : < 0,1%, arabe : 0,6%, malais : 1,2% (indonésien), bengali : <0,1%, turc : 1,9%, Vietnamien : 1,2 %, ourdou : <0,1 %, persan : 1,4 %, marathi : <0,1 %. TOTAL < 8 %. Plus d’un tiers des internautes n’ayant accès qu’à moins de 8% des contenus dans leur langue, cela n’a aucun sens.
Les observations constantes de l’OBDILCI, depuis 1998, montrent qu’il existe une sorte de relation entre le pourcentage d’utilisateurs dans une langue donnée et le pourcentage de contenus dans cette langue, une sorte de loi économique liant l’offre à la demande ; de plus, le rapport entre les pourcentages de contenus et d’utilisateurs dans une langue donnée ne sort guère de la fenêtre 0,5 – 2. Pour W3Techs, ce rapport est de 1,3/17,4 = 0,08 pour le chinois et de 0,1/4,34= 0,02 pour l’hindi, ce qui est tout à fait invraisemblable.
Entre 2011 et 2024, l’Internet a vu son nombre d’utilisateurs multiplié par plus de 3 et aujourd’hui de nombreux pays que l’on ne soupçonnerait pas ont des pourcentages de personnes connectées plus élevés que, par exemple, le Portugal ou la France (qui se situe juste autour de 85%), par exemple : Azerbaïdjan : 88,18%, Bhoutan : 86,84%, Brunei Darussalam : 99%, Kazakhstan : 92%, Libye : 88,4%.
Il n’est pas étonnant que la lingua franca de l’internet ne soit plus l’anglais, mais le multilinguisme, soutenu par une traduction par programme chaque jour plus efficace.
En conclusion, l’approche correcte pour la mesure des langues dans le Web est de mesurer les pourcentages de pages web par langue. La difficulté de traiter un espace aussi gigantesque justifie d’opter pour une approche de mesure par site web, à condition de prendre en compte que le même site peut avoir des pages dans plusieurs langues, ce que ne fait pas la source la plus utilisée W3Techs. L’approche la plus naturelle pour ce travail de mesure est d’utiliser un algorithme de reconnaissance des langues et de l’appliquer directement sur l’espace des sites Web. Cet espace étant lui même gigantesque, il est généralement sélectionné un espace réduit plus maitrisable pour appliquer la méthode : cela conduit inévitablement à un biais de sélection qu’il convient d’analyser et qui dans le contexte des langues peut être majeur.
Dans ce contexte, des méthodes alternatives, comme celles proposées par OBDILCI, ont toute leur place (ce qui bien entendu ne les exempt pas d’analyser les biais qu’elles-mêmes comportent). Comme pour toute statistique complexe, il est préférable de faire confiance à des méthodes soumises à publication scientifique, ce qui garantit en premier lieu la transparence totale de la méthode, un effort systématique d’analyse des biais, et de plus une meilleure probabilité que des erreurs ou des biais non traités ont pu être détectés par des collègues compétents chargé de la revue des publications ou ensuite des commentaires.

Les projets d’OBDILCI
- Indicateurs de la présence des langues et du multilinguisme dans l’Internet
- Les langues de France dans l’Internet
- Le français dans l’Internet
- Le portugais dans l’Internet
- L’espagnol dans l’Internet
- Rapports sur le multilinguisme de la Toile
- Cours
- IA et multilinguisme
- gTLDs linguistiques
- DILINET
- Projets pré-historiques
- Mort numérique des langues