PROYECTO PRINCIPAL-INGLES@WEB
Inglés@Web: un sesgo histórico

¿Cuál es realmente el porcentaje de inglés en la Web?
Le sorprende ver que nuestros resultados muestran el porcentaje de páginas Web en inglés alrededor del 20% cuando ve por todos los medios y consultas a buscadores valores entre el 50 y el 60%?
De hecho, está siendo testigo de una profunda y antigua mesinformación que merece atención y escrutinio. Esta página ofrece la información necesaria para comprender mejor lo que está en juego.
Esta mesinformación es el resultado de una combinación de factores:
- Una fuente sesgada: W3Techs.
- El hecho es que esta fuente es una empresa muy competente que ofrece estadísticas útiles y fiables sobre tecnologías Web y, además, también ofrece estadísticas sobre contenidos por lengua.
- El hecho es que esta fuente lleva funcionando desde 2011 y ha estado totalmente sola proporcionando datos de contenidos por lengua hasta 2017.
- El éxito mediático y de marketing de esta fuente que se ha visto amplificado por el sistema de ranking de los buscadores, Wikipedia y Statista, sin la prudencia requerida en los dos últimos casos.
- La baja visibilidad, comparativamente a W3Techs, de nuestro trabajo y sitio web (excepto en buscadores científicos como GoogleScholar).
W3TECHS una fuente sesgada cuando se refiere a lenguas
W3Techs es una empresa que ofrece información sobre el uso de varios tipos de tecnologías en la web y afirma proporcionar la fuente de información más fiable, más extensa y más relevante sobre el uso de tecnologías web.
Esta afirmación de fiabilidad está totalmente justificada, salvo en un elemento, que no es precisamente una tecnología web: el porcentaje de lenguas en contenidos. El método utilizado por W3Techs consiste en rastrear diariamente una muestra de sitios web y sondear la presencia de las diferentes tecnologías web que se analizan:
Content Management
Server-side Languages
Client-side Languages
JavaScript Libraries
CSS Frameworks
Web Servers
Web Panels
Operating Systems
Web Hosting
Data Centers
Reverse Proxies
DNS Servers
Email Servers
SSL Certificate Authorities
Content Delivery
Traffic Analysis Tools
Advertising Networks
Tag Managers
Social Widgets
Site Elements
Structured Data
Markup Languages
Character Encodings
Image File Formats
Top Level Domains
Server Locations
El último elemento de la lista es content languages; de hecho, las lenguas no son otra tecnología web y esto tiene implicaciones que hay que entender. A diferencia de las otras tecnologías web, no es una cuestión binaria de ser utilizado o no en un sitio web específico: varias lenguas diferentes pueden ser utilizados en el mismo sitio web y esto hace una fuerte diferencia que exploraremos más adelante.
La metodología utilizada por W3Techs para su encuesta es utilizar Tranco (la lista del millón de sitios web más visitados) como muestreo y aplicar diariamente su algoritmo de presencia sobre ese muestreo. Nótese que anteriormente, y hasta 2022 en que se terminó, se utilizaba la lista de 10 millones de sitios web proporcionada por Alexa. Nótese también que si bien es probablemente válida, para la mayoria de las tecnologias Web, la suposición de que la extrapolación del millón de sitios web más visitados a todo el ámbito web (que alberga más de 200 millones de sitios web) es aplicable, no lo es en el caso de las lenguas de los sitios web, ya que es probable que los sitios web más visitados concentren el uso de las lenguas más utilizadas, y especialmente el inglés, creando un efecto de lupa.
Así pues, centrémonos ahora en los diferentes sesgos de utilizar el método de encuesta sobre tecnología web para las lenguas de contenidos. Son diferentes sesgos que hay que tener en cuenta:
- El sesgo de reconocimiento lingüístico. El algoritmo de reconocimiento de idiomas tiene una tasa de error considerada inferior al 10% y tiende a reconocer el inglés por encima de su prevalencia real. Se trata de un sesgo marginal, aunque favorece al inglés.
- El sesgo de selección. Un millón de sitios web representan menos del 0,5% del universo web total y en ningún caso pueden considerarse representativos del total. De hecho, favorece a los idiomas más utilizados en la Red y especialmente al inglés.
- Cómputo de lenguas sobre sitios web en lugar de páginas web. El cálculo correcto de las lenguas en los contenidos debe hacerse sobre las páginas web, dividiendo el total de páginas web en una lengua determinada por el total de páginas web. Hay que admitir que el tamaño de la Web, estimado en más de 40.000 millones de páginas web, hace casi imposible el cómputo y es comprensible la simplificación del método. Pero hay una condición que debe respetarse para que esa simplificación sea viable: prestar la debida atención al hecho de que muchos sitios web son multilingües y esa propiedad debe tenerse en cuenta en el método para evitar un enorme sesgo que favorezca al inglés (el cual es el sesgo principal de W3Techs, el sesgo de multilinguismo, ver abajo).
- Hay otro sesgo en ese escenario de computación por sitios web en lugar de páginas web: el sesgo de la página de inicio. La elección, como hace W3Techs, de aplicar el algoritmo de reconocimiento en la página de inicio del sitio web conlleva grandes riesgos. Es habitual que muchos sitios web no ingleses se esfuercen por incluir algún texto en inglés en su página de inicio, ya sea por síntesis (como se hace habitualmente con los resúmenes de artículos científicos escritos en idiomas distintos del inglés) o por accidente (por ejemplo, botones en inglés). Existe entonces la posibilidad de que el algoritmo identifique erróneamente esta página de inicio como inglesa.
- Otro sesgo en ese escenario es la clasificación, por error, de sitios web no ingleses como ingleses. Esto puede ocurrir bien porque la página de inicio contenga algún texto en inglés (caso precedente), pero tambien porque el sitio web no funcione y aún así se clasifique como sitio web en inglés debido a un mensaje en inglés informando del error. La magnitud de este sesgo podría rondar el 10%.
Hay otro punto que cuestiona los resultados de W3Techs. W3Techs presenta los resultados en términos de porcentaje para 38 idiomas, seguidos de una lista ordenada de unos 200 idiomas para los que informa de una cifra inferior al 0,1% para cada uno de ellos.
Sin embargo, si se hace la suma de los porcentajes de las 38 primeras lenguas (el 23/04/2024) el resultado es exactamente 99,90%. Esto significa que el resto de los 200 idiomas juntos representan menos del 0,1% de la Web lo que suena un poco raro, ya que implica que en promedio esos 200 idiomas representarán individualmente unos 0,0005% lo que parece inverosímil.
Para hacer una comparación, si comprobamos el porcentaje restante de contenidos de las 361 lenguas que estamos computando en nuestro modelo, sigue representando el 1,76% en nuestra última versión, cifra coherente con el hecho de que el resto de lenguas corresponde al 3,42% restante de población L1+L2 y al 2,65% de población conectada.
El principal sesgo de W3TECHS: no prestar la debida atención al multilingüismo de los sitios web
La metodología de W3Techs se describe aquí : https://w3techs.com/technologies. No es una descripción totalmente detallada y transparente como la que ofrecería un artículo científico. Por lo que se lee, se entiende que a cada web se le atribuye una lengua única. También se asume que la lengua de trabajo por defecto es el inglés, lo que implica que los sitios web multilingües (como Facebook) se clasifican como sitios web en inglés. La metodología se refiere a «sitios web relevantes«, pero no hay ninguna descripción sobre el tratamiento de los sitios web que no responden con los contenidos esperados y también podemos suponer que una proporción de sitios web con errores pueden ser reconocidos como sitios web en inglés (tenga en cuenta que en el muestreo Tranco hemos identificado hasta un 20% de sitios web con error, ya sea 401 u otro).
Hemos analizado más a fondo las consecuencias de este sesgo e incluso hemos encontrado una forma de corregirlo; el análisis se publica en el artículo publicado en 2024 en Forum for Linguistic Studies (FLS) “Is it True that More Than Half of Web Contents are in English? If Web Multilingualism is Paid Due Attention, then No!“. Obsérvese que la corrección de sesgos lleva a una cifra de inglés comparable a las cifras de OBDILCI. Obsérvese también que el artículo hace referencia a otros dos conjuntos de cifras de contenidos en inglés en el mismo rango (20%-30%). Una procede de un artículo científico centrado en los sitios web dentro de los dominios de nivel superior de la Unión Europea (antes del Brexit, es decir incluyendo el Reino Unido y otros paises de lengua inglesa), la segunda de otra empresa de software Netsweeper, que parece proceder analizando páginas web en lugar de sitios web, lo que la exonera del sesgo de multilinguismo, e reporta un enorme muestreo de 15.000 millones de páginas web.
Si prefieres una demostración sencilla ilustrada con un ejemplo concreto en lugar de leer un artículo científico, adelante, compruébalo ahi:
Inglés@Web: un sesgo histórico
La situación de sobrevalorar la realidad del porcentaje de contenidos en inglés no es algo nuevo. De hecho, existe casi desde el nacimiento de la Web. Las siguientes curvas muestran la diferencia entre lo que nuestro observatorio ha medido y los medios de comunicación que informan sobre esos datos.
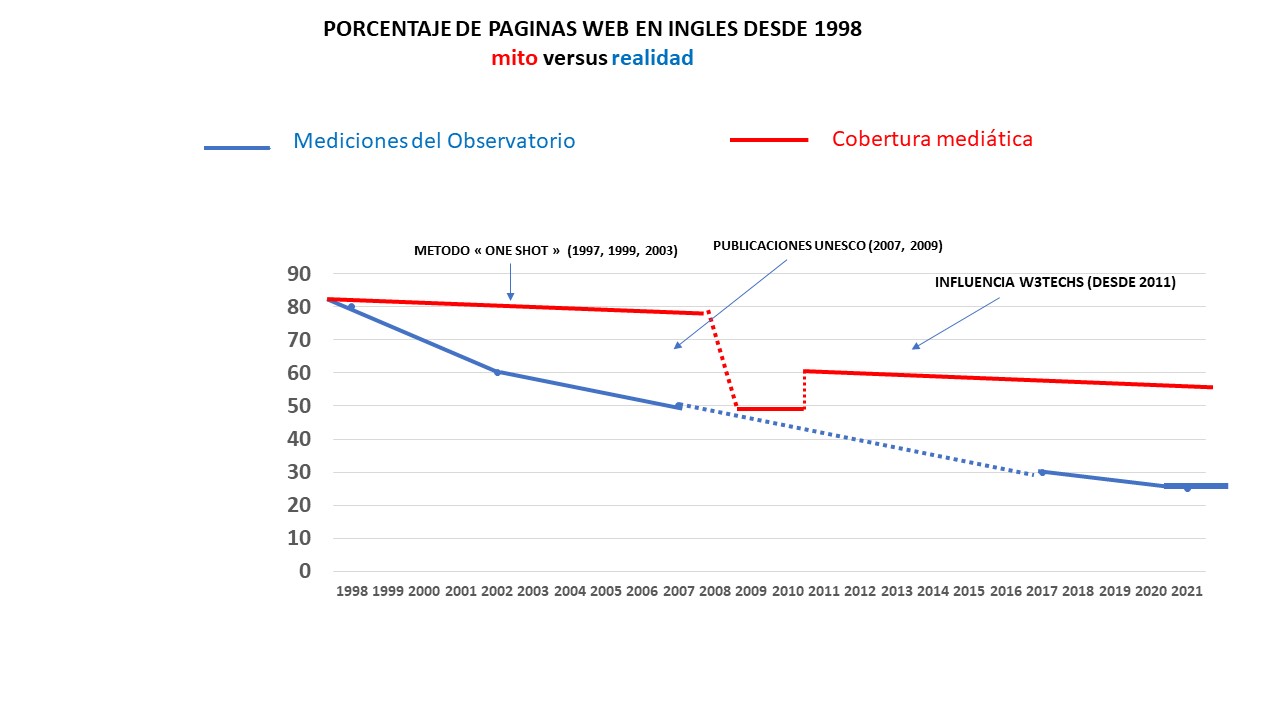
Esta situación se ha documentado en muchos artículos revisados por pares desde el principio. Puede comprobarlo, por ejemplo:
- “Twelve years of measuring linguistic diversity on the Internet: balance and perspectives”, UNESCO publications for the World Summit on the Information Society. CI-2009/WS/1- (aussi en français – Русский)
- “Internet and linguistic diversity: the cyber-geography of languages with the largest number of speakers” in LinguaPax Review 2021, Language Technologies and Language Diversity, page 9. Also, in Spanish and Catalan.
- “Resource: Indicators on the Presence of Languages in Internet”, SIGUL2022 a workshop of LCREC22, Marseille, 6/2022 – français, español, portuguese.
- “Cyber-geography of languages. Part 1: method, results and focus on English”, International Review of Information Ethics, vol. 32 no. 1 (2022): Emerging Technologies and Changing Dynamics of Information (ETCDI) special issue.
El hecho de que autoridades como Wikipedia o Statista prefieran citar cifras no científicas a cifras respaldadas por expertos es claramente parte del problema. En ambos casos hemos intentado abrir los ojos a esos proveedores de fuentes. En el caso de STATISTA nuestro bien documentado correo quedó sin respuesta y compartimos con otros la visión que la gestión de las fuentes por parte de STATISTA levanta serios problemas de ética en la campo de la investigación. En el caso de Wikipedia por fin se han hecho algunos progresos.
UNA MIRADA AL CONTEXTO Y EL USO DE CIERTA RACIONALIDAD
Cuál es el contexto de ese tema? Por un lado, W3Techs muestra, en su página histórica, un porcentaje de inglés en la web casi estable de 2011 a 2024, entre el 50 y el 60%. Nótese que hasta hace poco este histograma comenzaba en 2011. Por otro lado, la Internet ha evolucionado, de 2011 a 2024, con las siguientes cifras (fuentes : InternetWorldStats para 2011 y OBDILCI para 2024, nótese que son cifras L1+L2)
En 2011
- El número mundial de personas conectadas es de 1 966 514 816 (28,7% de la población mundial)
- De los cuales el número de angloparlantes conectados es de 536,6 M (27,3% de las personas conectadas)
En 2024
- El número mundial de personas conectadas es de 6 800 888 461 (63,19% de la población mundial)
- De los cuales, el número de anglófonos conectados es de 1 186 451 052 (15,79 % de las personas conectadas)
Esto representa un descenso relativo de angloparlantes conectados a la Internet del 72,8%. Por supuesto, el número de internautas angloparlantes ha aumentado en gran medida en 13 años, pero muy por debajo de la suma del resto de internautas de otras lenguas (para su información, según el conjunto de datos Ethnologue #27, los angloparlantes L1+L2 representan 1 515 231 760 personas, lo que supone el 14,13% del total de hablantes L1+L2) . Para que los contenidos en inglés se mantengan estables en proporción en este contexto, significaría que han compensado ese descenso relativo aumentando la producción de contenidos anglófonos por usuario ¡en un 72,8%!
En 2024, fruto de la evolución de la demografía de Internet, el porcentaje de hablantes de chino conectados ha superado al de angloparlantes y ya es del 17,41% y el mismo valor para los hablantes de hindi es del 4,34%. Juntos representan más del 20% de los internautas y siguiendo las cifras de W3Techs sólo representarían menos del 1,4% de los contenidos: esto es un disparate.
En nuestra última medición (V5.1, marzo de 2024), si se suman los internautas chinos, hindi, árabe, malayo, bengalí, turco, vietnamita, urdu, persa y marathi los resultados alcanzan el 35,81% del total de internautas. Si se suman los contenidos se alcanza el 34,45%.
Para las mismas lenguas, W3Techs suma menos del 8% de los contenidos: Chino: 1,3%, hindi: < 0,1%, árabe: 0,6%, malayo: 1,2% (indonesio), bengalí: <0,1%, turco: 1,9%, vietnamita: 1,2%, urdu: <0,1%, persa: 1,4%, marathi: <0,1%, TOTAL < 8%. Más de un tercio de los usuarios tienen acceso a menos del 8% de los contenidos en su idioma, esto es un disparate.
Las observaciones coherentes de OBDILCI, desde 1998, han sido que existe algún tipo de relación entre el porcentaje de usuarios en un idioma determinado y el porcentaje de contenidos en este idioma, una especie de ley económica que vincula la oferta a la demanda; además, el ratio entre los contenidos y los porcentajes de usuarios en un idioma determinado apenas se sale de la ventana 0,5 – 2. Para W3Techs esta relación es de 1,3/17,4 = 0,08 para el chino y de 0,1/4,34= 0,02 para el hindi lo cual es totalmente inverosímil.
Entre 2011 y 2024, la Internet se ha multiplicado por más de 3 y hoy muchos países de los que uno no sospecharía tienen porcentajes de personas conectadas superiores a, por ejemplo, Portugal o Francia (que apenas rondan el 85%): Azerbaiyán: 88,18%, Bután: 86,84%, Brunei Darussalam: 99%, Kazajstán: 92%, Libia: 88,4%.
No es de extrañar que la lingua franca de la Internet ya no sea el inglés, sino el multilingüismo apoyado por una traducción por programa cada día más eficaz.
En conclusión, el enfoque correcto para medir las lenguas en la Red es medir los porcentajes de páginas web por lengua. La dificultad de tratar con un espacio tan gigantesco justifica optar por un enfoque de medición por sitio web, siempre y cuando se tenga en cuenta que un mismo sitio puede tener páginas en varios idiomas, cosa que la fuente más utilizada, W3Techs, no hace. El enfoque más natural para este trabajo de medición es utilizar un algoritmo de reconocimiento de lengua y aplicarlo directamente al espacio del sitio web. Como este espacio es de por sí gigantesco, generalmente se selecciona un espacio más pequeño y controlable para aplicar el método: esto conduce inevitablemente a un sesgo de selección que es necesario analizar y que en el contexto de las lenguas puede ser mayor.
En este contexto, los métodos alternativos, como los propuestos por OBDILCI, tienen todo su lugar (lo que por supuesto no les exime de analizar los sesgos que ellos mismos contienen). Como ocurre con todas las estadísticas complejas, es preferible confiar en métodos sujetos a publicación científica, lo que garantiza en primer lugar la total transparencia del método, un esfuerzo sistemático de análisis de los sesgos y, además, una mayor probabilidad de que los errores o sesgos no abordados puedan haber sido detectados por colegas competentes encargados de revisar las publicaciones o de comentarlas posteriormente.

Proyectos OBDILCI
- Indicadores de la presencia de lenguas en la Internet
- Las lenguas de Francia en la Internet
- El francés en la Internet
- El portugués en la Internet
- El español en la Internet
- IA y multilinguismo
- gTLDs lingüísticos
- Proyectos pre-históricos
- Muerte digital de las lenguas