PROJECTO PRINCIPAL-INGLES@WEB
Inglês@Web: um viés histórico

Qual é realmente a percentagem de inglês na Web?
Surpreende-o ver os nossos resultados mostrarem a percentagem de páginas Web em inglês cerca de 20% quando se vê em todos os meios de comunicação e consultas aos motores de busca valores entre 50 e 60%?
Na verdade, está a assistir a uma desinformação profunda e antiga que merece atenção e escrutínio. Esta página oferece as informações necessárias para compreender melhor as questões em causa.
Esta desinformação é o resultado de uma combinação de factores:
- Uma fonte tendenciosa: W3Techs.
- O facto de esta fonte ser uma empresa muito competente que oferece estatísticas úteis e fiáveis sobre tecnologias Web e que, por outro lado, oferece também estatísticas sobre conteúdos por língua.
- O facto de esta fonte estar a funcionar desde 2011 e ter sido a única a fornecer dados de conteúdos por língua até 2017.
- O sucesso comercial e mediático desta fonte que foi amplificado pelo sistema de classificação dos motores de busca, da Wikipédia e do Statista, sem a prudência necessária nos dois últimos casos.
- A baixa visibilidade do nosso trabalho e do nosso sítio Web (exceto em motores de busca científicos como GoogleScholar).
W3TECHS uma fonte tendenciosa quando se refere a línguas
W3Techs é uma empresa que oferece informações sobre a utilização de vários tipos de tecnologias na Web e afirma fornecer a fonte de informação mais fiável, mais extensa e mais relevante sobre a utilização de tecnologias Web.
Esta afirmação de fiabilidade é totalmente justificada, exceto por um item, que não é precisamente uma tecnologia Web: a percentagem de línguas nos conteúdos. O método utilizado pela W3Techs consiste em rastrear diariamente uma amostragem de sítios Web e verificar a presença das diferentes tecnologias Web analisadas:
Content Management
Server-side Languages
Client-side Languages
JavaScript Libraries
CSS Frameworks
Web Servers
Web Panels
Operating Systems
Web Hosting
Data Centers
Reverse Proxies
DNS Servers
Email Servers
SSL Certificate Authorities
Content Delivery
Traffic Analysis Tools
Advertising Networks
Tag Managers
Social Widgets
Site Elements
Structured Data
Markup Languages
Character Encodings
Image File Formats
Top Level Domains
Server Locations
O último item da lista é Content Languages; de facto, as linguagens não são outra tecnologia Web, o que tem implicações a compreender. Ao contrário das outras tecnologias Web, não se trata de uma questão binária de serem ou não utilizadas num sítio Web específico: podem ser utilizadas várias línguas diferentes no mesmo sítio Web, o que faz uma grande diferença que iremos explorar mais adiante.
A metodologia utilizada pela W3Techs para o seu inquérito consiste em utilizar Tranco (a lista dos milhões de sítios Web mais visitados) como amostragem e aplicar diariamente o seu algoritmo de presença nessa amostragem. Note-se que anteriormente, e até 2022 quando foi terminado, utilizavam a lista de 10 milhões de sítios Web fornecida pelo Alexa. Note-se também que, embora seja válido para tecnologias Web o pressuposto de que a extrapolação de um milhão de sítios Web mais visitados para todo o universo da Web (que contém mais de 200 milhões de sítios Web) é correta, o mesmo não acontece com as línguas dos sítios Web, uma vez que é provável que os sítios Web mais visitados concentrem a utilização das línguas mais utilizadas, em especial o inglês, criando um efeito de lupa.
Assim, concentremo-nos agora nos diferentes preconceitos da utilização do método de inquérito Tecnologia Web para as línguas de conteúdo. São diferentes preconceitos que devem ser considerados:
- O viés de reconhecimento da língua. O algoritmo de reconhecimento da língua tem uma taxa de erro considerada inferior a 10% e tende a reconhecer o inglês acima da prevalência real. Trata-se de um desvio marginal, embora favoreça o inglês.
- O viés de seleção. Um milhão de sítios Web representa menos de 0,5% do universo total da Web e não pode, de modo algum, ser considerado representativo do total. De facto, favorece as línguas mais utilizadas na Web, especialmente o inglês.
- Cálculo das línguas em sítios Web em vez de páginas Web. O cálculo correto das línguas nos conteúdos deve ser feito nas páginas Web, dividindo o total de páginas Web numa determinada língua pelo total de páginas Web. Há que admitir que a dimensão da Web, estimada em mais de 40 mil milhões de páginas Web, torna o cálculo quase impossível e a simplificação do método é compreensível. Mas há uma condição a respeitar para que essa simplificação seja viável: prestar a devida atenção ao facto de muitos sítios Web serem multilingues e essa propriedade ter de ser tida em conta no método para evitar um enorme enviesamento a favor do inglês (o viés do multilinguismo que é o principal viés das W3Techs, veja abaixo).
- Há outro viés nesse cenário de computação por sites em vez de páginas da web: o viés da página inicial. A escolha, feita pela W3Techs, de aplicar o algoritmo de reconhecimento na página inicial do site acarreta riscos elevados. É comum que muitos sites não ingleses se esforcem para incluir algum texto em inglês em sua página inicial, seja de síntese (como é feito rotineiramente para resumos de artigos científicos escritos em outro idioma que não o inglês) ou por acidente (botões em inglês, por exemplo). ). Existe então uma chance de que o algoritmo identifique erroneamente esta página inicial como inglesa.
- Outra distorção neste cenário é a classificação, por erro, de sítios Web não ingleses como sendo ingleses. Isto pode acontecer quer porque a página de entrada contém algum texto em inglês (caso precedente), quer porque o sítio não está a funcionar e continua a ser classificado como sítio inglês devido a uma mensagem em inglês que comunica o erro. A dimensão deste desvio pode ser de cerca de 10%.
Há outro ponto que põe em causa os resultados da W3Techs. A W3Techs apresenta os resultados em termos percentuais para 38 línguas, seguidos de uma lista ordenada de cerca de 200 línguas para as quais indica um valor inferior a 0,1% para cada uma delas.
No entanto, se as percentagens das primeiras 38 línguas forem somadas (em 23/04/2024), o resultado é exatamente 99,90%. Isso significa que o restante das 200 línguas juntas representa menos de 0,1% da Web, o que soa um pouco estranho, pois implica que em média essas 200 línguas representarão individualmente cerca de 0,0005%, o que parece implausível.
Para comparação, se verificarmos a percentagem restante de conteúdo das 361 línguas que estamos a calcular no nosso modelo, ainda representa 1,76% na nossa versão mais recente, um valor consistente com o facto de as restantes línguas corresponderem aos restantes 3,42% da população L1+L2 e 2,65% da população conectada.
O principal viés do W3TECHS: não prestar a devida atenção ao multilinguismo dos sítios Web
A metodologia da W3Techs é descrita aqui : https://w3techs.com/technologies. Não se trata de uma descrição totalmente pormenorizada e transparente como a que seria oferecida num artigo científico. Do que se lê, subentende-se que a cada sítio Web é atribuída uma única língua. Parte-se também do princípio de que a língua de trabalho por defeito é o inglês, o que implica que os sítios multilingues (como o Facebook) são classificados como sítios em inglês. A metodologia refere-se a “sites relevantes“, mas não há descrição sobre o tratamento dos sítios Web que não respondem com os conteúdos esperados e podemos também assumir que uma proporção de sítios Web com erros pode ser reconhecida como sítios Web em inglês (note-se que na amostragem Tranco identificámos até 20% de sítios Web com erros, quer 401 quer outros).
Analisámos mais aprofundadamente as consequências deste enviesamento e encontrámos mesmo uma forma de o corrigir; a análise está publicada no artigo em Forum for Linguistic Studies (FLS) “Is it True that More Than Half of Web Contents are in English? If Web Multilingualism is Paid Due Attention, then No!“ Note-se que a correção de viés conduz a um valor do inglês comparável aos valores do OBDILCI. Note-se também que o documento faz referência a dois outros conjuntos de valores para conteúdos em inglês no mesmo intervalo (20%-30%). Um deles provém de um artigo científico que se centra em sítios Web dentro dos domínios de topo da União Europeia (antes do Brexit e incluindo países de língua inglesa), o segundo de outra empresa de software Netsweeper, que parece analisar páginas Web em vez de sítios Web (que evitam o viés do multilinguismo) e apresenta uma amostragem enorme de 15 mil milhões de páginas Web.
Se preferir uma demonstração simples ilustrada por um exemplo em vez de ler um artigo científico, vá em frente e verifique:
UMA ATUALIZAÇÃO IMPORTANTE SOBRE ESTE ASSUNTO (julho de 2026): Analisámos agora a mesma amostra que a W3Techs e constatámos que a percentagem de páginas web em inglês é de 20,13%, o que confirma as nossas previsões. A percentagem de sítios web que possuem uma versão em inglês é de 67,52%. Qual é, então, o significado do valor apresentado pela W3Techs de 49,6%? Certamente não se trata da percentagem de páginas web, mas é um valor demasiado baixo para se referir à percentagem de versões em inglês nos sites… É impossível determinar, dada a falta de documentação sobre o método. Suspeitamos que este valor se refira a um conceito de «percentagem de sites na amostra da Tranco que têm o inglês como “língua principal“. O conceito de língua principal aplica-se aos seres humanos e é também designado por língua materna ou primeira língua. No entanto, este conceito dificilmente se aplica a sites; em sites multilingues, é o utilizador que determina qual é a língua principal, seja implicitamente (o site deteta a língua predefinida do telemóvel ou do computador) ou explicitamente, selecionando a opção de língua da sua preferência num menu de línguas (ou países). Se quiser saber mais sobre a nossa nova linha de investigação e a sua produção de novos indicadores sobre o multilinguismo na Web, consulte o nosso novo projeto principal MECILDI.
Inglês@Web: um viés histórico
A situação de sobrevalorização da realidade da percentagem de conteúdos em inglês não é nova. De facto, existe quase desde o nascimento da Web. As curvas seguintes mostram a diferença entre o que o nosso observatório mediu e os meios de comunicação social que divulgam esses dados.
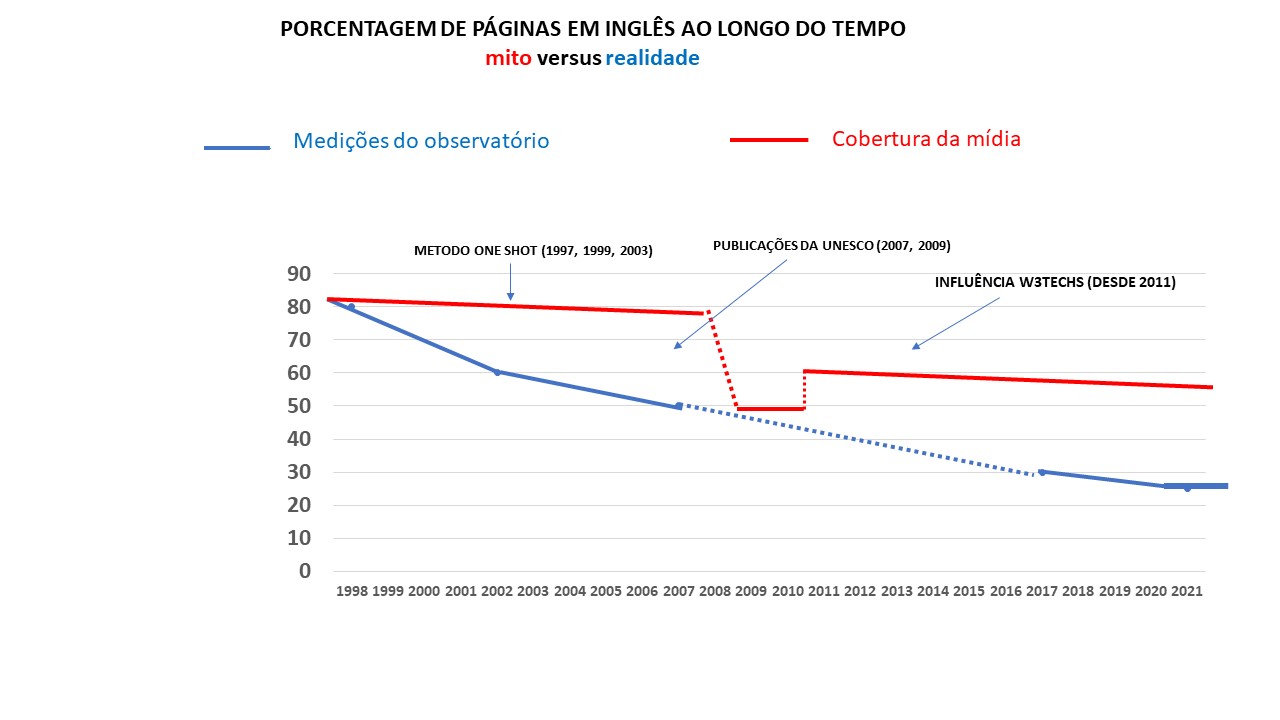
Esta situação tem sido documentada em muitos artigos revistos por pares desde o início. Pode verificar, por exemplo:
- “Twelve years of measuring linguistic diversity on the Internet: balance and perspectives”, UNESCO publications for the World Summit on the Information Society. CI-2009/WS/1- (aussi en français – Русский)
- “Internet and linguistic diversity: the cyber-geography of languages with the largest number of speakers” in LinguaPax Review 2021, Language Technologies and Language Diversity, page 9. Also, in Spanish and Catalan.
- “Resource: Indicators on the Presence of Languages in Internet”, SIGUL2022 a workshop of LCREC22, Marseille, 6/2022 – français, español, portuguese.
- “Cyber-geography of languages. Part 1: method, results and focus on English”, International Review of Information Ethics, vol. 32 no. 1 (2022): Emerging Technologies and Changing Dynamics of Information (ETCDI) special issue.
O facto de autoridades como a Wikipédia ou a Statista preferirem citar números não científicos em vez de números apoiados por revisores de pares é claramente parte do problema. Em ambos os casos, tentámos abrir os olhos a esses fornecedores de fontes. No caso da STATISTA o nosso bem documentado correio eletrónico permaneceu sem resposta e partilhamos a opinião de que a gestão das fontes pelo STATISTA levanta sérias questões éticas no domínio da investigação. No caso da Wikipedia finalmente foram feitos alguns progressos.
UM OLHAR SOBRE O CONTEXTO E A UTILIZAÇÃO DE ALGUMA RACIONALIDADE
Qual é o contexto desse tema? Por um lado, a W3Techs mostra, na sua página histórica, uma percentagem de inglês na Web quase estável de 2011 a 2024, entre 50 e 60%. Note-se que até há pouco tempo este histograma começava em 2011. Por outro lado, a Internet tem evoluído, de 2011 a 2024, com os seguintes valores (fontes : InternetWorldStats para 2011 e OBDILCI para 2024, note-se que são valores L1+L2)
Em 2011
- O número mundial de pessoas ligadas à Internet é de 1 966 514 816 (28,7% da população mundial)
- Dos quais o número de falantes de inglês ligados é de 536,6 M (27,3% das pessoas ligadas)
Em 2024
- O número mundial de pessoas ligadas à Internet é de 6 800 888 461 (63,19% da população mundial)
- Dos quais o número de falantes de inglês ligados é de 1 186 451 052 (15,79 % das pessoas ligadas)
Isto representa um declínio relativo de falantes de inglês ligados à Internet de 72,8%. É claro que o número de internautas de língua inglesa aumentou largamente em 13 anos, mas muito abaixo da soma dos restantes internautas de outras línguas (para sua informação, com base no conjunto de dados Ethnologue #27, os falantes de inglês L1+L2 representam 1 515 231 760 pessoas, o que corresponde a 14,13% do total de falantes de L1+L2). Para que os conteúdos em inglês se mantivessem estáveis em proporção neste contexto, isso significaria que compensaram esse declínio relativo aumentando a produção de conteúdos por utilizador de língua inglesa em 72,8%!
Em 2024, resultado da evolução da demografia da Internet, a percentagem de falantes de chinês conectados ultrapassou os falantes de inglês e é agora de 17,41% e o mesmo valor para os falantes de hindi é de 4,34%. Em conjunto, representam mais de 20% dos utilizadores da Internet e, segundo os números da W3Tech, representariam apenas menos de 1,4% dos conteúdos: isto é um disparate.
Desde a nossa última medição (V5.1, março de 2024), se os internautas chineses, hindi, árabes, malaios, bengalis, turcos, vietnamitas, urdu, persas e maratas forem somados, os resultados atingem 35,81% do total de internautas. Se os conteúdos forem somados, atingem 34,45%.
Para as mesmas línguas, a W3Techs soma menos de 8% dos conteúdos: Chinês: 1,3%, Hindi: < 0,1%, Árabe: 0,6%, Malaio: 1,2% (Indonésio), Bengali: <0,1%, Turco: 1,9%, Vietnamita: 1,2%, Urdu: <0,1%, Persa: 1,4%, Marathi: <0,1%, TOTAL < 8%. Mais de um terço dos utilizadores tem acesso a menos de 8% dos conteúdos na sua língua, isto é um disparate.
As observações consistentes do OBDILCI, desde 1998, têm sido que existe uma espécie de relação entre a percentagem de utilizadores numa dada língua e a percentagem de conteúdos, uma espécie de lei económica que liga a oferta à procura; além disso, o rácio entre as percentagens de conteúdos e de utilizadores numa dada língua dificilmente está fora da janela 0,5 – 2. Para a W3Techs, este rácio é de 1,3/17,4 = 0,08 para o chinês e 0,1/4,34= 0,02 para o hindi, o que é totalmente implausível.
Entre 2011 e 2024, a Internet cresceu mais de 3 vezes e, atualmente, muitos países de que não se suspeitaria têm percentagens de pessoas ligadas superiores, por exemplo, a Portugal ou a França (que rondam os 85%): Azerbaijão: 88,18%, Butão: 86,84%, Brunei Darussalam: 99%, Cazaquistão: 92%, Líbia: 88,4%
Não é de admirar que a língua franca da Internet já não seja o inglês, mas sim o multilinguismo apoiado por uma tradução por programa cada vez mais eficaz.
Em conclusão, a abordagem correcta para medir as línguas na Web consiste em medir as percentagens de páginas Web por língua. A dificuldade de lidar com um espaço tão gigantesco justifica que se opte por uma abordagem de medição por sítio Web, desde que se tenha em conta que o mesmo sítio pode ter páginas em várias línguas, o que não acontece com a fonte mais utilizada, o W3Techs. A abordagem mais natural para este trabalho de medição é utilizar um algoritmo de reconhecimento de línguas e aplicá-lo diretamente ao espaço do sítio Web. Uma vez que este espaço é gigantesco, selecciona-se geralmente um espaço mais pequeno e mais controlável para aplicar o método: isto conduz inevitavelmente a um viés de seleção que tem de ser analisado e que, no contexto das línguas, pode ser importante.
Neste contexto, os métodos alternativos, como os propostos pelo OBDILCI, têm o seu lugar (o que, evidentemente, não os dispensa de analisar os enviesamentos que eles próprios contêm). Como em todas as estatísticas complexas, é preferível confiar em métodos submetidos a publicação científica, o que garante, em primeiro lugar, a total transparência do método, um esforço sistemático de análise dos enviesamentos e, além disso, uma maior probabilidade de que os erros ou enviesamentos não abordados possam ter sido detectados por colegas competentes responsáveis pela revisão das publicações ou por comentários posteriores.

Projetos de OBDILCI
- Indicadores da presença das línguas e multilinguismo na Internet
- As línguas da França na Internet
- Francês na Internet
- Português na Internet
- Espanhol na Internet
- Multilinguismo en la Web
- Cursos
- IA e multilinguismo
- gTLDs linguisticos
- DILINET
- Projetos pré-históricos
- Projeto Digital Language Death